













Backups
Apache Cassandra stores data in immutable SSTable files. Backups in Apache Cassandra database are backup copies of the database data that is stored as SSTable files. Backups are used for several purposes including the following:
-
To store a data copy for durability
-
To be able to restore a table if table data is lost due to node/partition/network failure
-
To be able to transfer the SSTable files to a different machine; for portability
Types of Backups
Apache Cassandra supports two kinds of backup strategies.
-
Snapshots
-
Incremental Backups
A snapshot is a copy of a table’s SSTable files at a given time,
created via hard links.
The DDL to create the table is stored as well.
Snapshots may be created by a user or created automatically.
The setting snapshot_before_compaction in the cassandra.yaml file determines if
snapshots are created before each compaction.
By default, snapshot_before_compaction is set to false.
Snapshots may be created automatically before keyspace truncation or dropping of a table by
setting auto_snapshot to true (default) in cassandra.yaml.
Truncates could be delayed due to the auto snapshots and another setting in
cassandra.yaml determines how long the coordinator should wait for
truncates to complete.
By default Cassandra waits 60 seconds for auto snapshots to complete.
An incremental backup is a copy of a table’s SSTable files created by
a hard link when memtables are flushed to disk as SSTables.
Typically incremental backups are paired with snapshots to reduce the backup time
as well as reduce disk space.
Incremental backups are not enabled by default and must be enabled explicitly in cassandra.yaml (with
incremental_backups setting) or with nodetool.
Once enabled, Cassandra creates a hard link to each SSTable flushed or streamed
locally in a backups/ subdirectory of the keyspace data.
Incremental backups of system tables are also created.
Data Directory Structure
The directory structure of Cassandra data consists of different directories for keyspaces, and tables with the data files within the table directories. Directories backups and snapshots to store backups and snapshots respectively for a particular table are also stored within the table directory. The directory structure for Cassandra is illustrated in Figure 1.
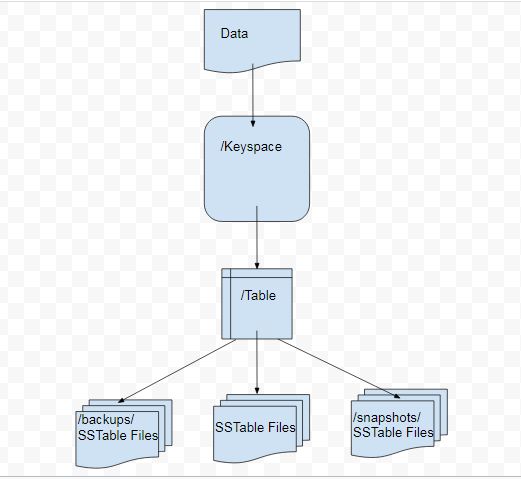
Figure 1. Directory Structure for Cassandra Data
Setting Up Example Tables for Backups and Snapshots
In this section we shall create some example data that could be used to
demonstrate incremental backups and snapshots.
We have used a three node Cassandra cluster.
First, the keyspaces are created.
Then tables are created within a keyspace and table data is added.
We have used two keyspaces cqlkeyspace and catalogkeyspace with two tables within
each.
Create the keyspace cqlkeyspace:
CREATE KEYSPACE cqlkeyspace
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};Create two tables t and t2 in the cqlkeyspace keyspace.
USE cqlkeyspace;
CREATE TABLE t (
id int,
k int,
v text,
PRIMARY KEY (id)
);
CREATE TABLE t2 (
id int,
k int,
v text,
PRIMARY KEY (id)
);Add data to the tables:
INSERT INTO t (id, k, v) VALUES (0, 0, 'val0');
INSERT INTO t (id, k, v) VALUES (1, 1, 'val1');
INSERT INTO t2 (id, k, v) VALUES (0, 0, 'val0');
INSERT INTO t2 (id, k, v) VALUES (1, 1, 'val1');
INSERT INTO t2 (id, k, v) VALUES (2, 2, 'val2');Query the table to list the data:
SELECT * FROM t;
SELECT * FROM t2;results in
id | k | v
----+---+------
1 | 1 | val1
0 | 0 | val0
(2 rows)
id | k | v
----+---+------
1 | 1 | val1
0 | 0 | val0
2 | 2 | val2
(3 rows)Create a second keyspace catalogkeyspace:
CREATE KEYSPACE catalogkeyspace
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};Create two tables journal and magazine in catalogkeyspace:
USE catalogkeyspace;
CREATE TABLE journal (
id int,
name text,
publisher text,
PRIMARY KEY (id)
);
CREATE TABLE magazine (
id int,
name text,
publisher text,
PRIMARY KEY (id)
);Add data to the tables:
INSERT INTO journal (id, name, publisher) VALUES (0, 'Apache Cassandra Magazine', 'Apache Cassandra');
INSERT INTO journal (id, name, publisher) VALUES (1, 'Couchbase Magazine', 'Couchbase');
INSERT INTO magazine (id, name, publisher) VALUES (0, 'Apache Cassandra Magazine', 'Apache Cassandra');
INSERT INTO magazine (id, name, publisher) VALUES (1, 'Couchbase Magazine', 'Couchbase');Query the tables to list the data:
SELECT * FROM catalogkeyspace.journal;
SELECT * FROM catalogkeyspace.magazine;results in
id | name | publisher
----+---------------------------+------------------
1 | Couchbase Magazine | Couchbase
0 | Apache Cassandra Magazine | Apache Cassandra
(2 rows)
id | name | publisher
----+---------------------------+------------------
1 | Couchbase Magazine | Couchbase
0 | Apache Cassandra Magazine | Apache Cassandra
(2 rows)Snapshots
In this section, we demonstrate creating snapshots.
The command used to create a snapshot is nodetool snapshot with the usage:
$ nodetool help snapshotresults in
NAME
nodetool snapshot - Take a snapshot of specified keyspaces or a snapshot
of the specified table
SYNOPSIS
nodetool [(-h <host> | --host <host>)] [(-p <port> | --port <port>)]
[(-pp | --print-port)] [(-pw <password> | --password <password>)]
[(-pwf <passwordFilePath> | --password-file <passwordFilePath>)]
[(-u <username> | --username <username>)] snapshot
[(-cf <table> | --column-family <table> | --table <table>)]
[(-kt <ktlist> | --kt-list <ktlist> | -kc <ktlist> | --kc.list <ktlist>)]
[(-sf | --skip-flush)] [(-t <tag> | --tag <tag>)] [--] [<keyspaces...>]
OPTIONS
-cf <table>, --column-family <table>, --table <table>
The table name (you must specify one and only one keyspace for using
this option)
-h <host>, --host <host>
Node hostname or ip address
-kt <ktlist>, --kt-list <ktlist>, -kc <ktlist>, --kc.list <ktlist>
The list of Keyspace.table to take snapshot.(you must not specify
only keyspace)
-p <port>, --port <port>
Remote jmx agent port number
-pp, --print-port
Operate in 4.0 mode with hosts disambiguated by port number
-pw <password>, --password <password>
Remote jmx agent password
-pwf <passwordFilePath>, --password-file <passwordFilePath>
Path to the JMX password file
-sf, --skip-flush
Do not flush memtables before snapshotting (snapshot will not
contain unflushed data)
-t <tag>, --tag <tag>
The name of the snapshot
-u <username>, --username <username>
Remote jmx agent username
--
This option can be used to separate command-line options from the
list of argument, (useful when arguments might be mistaken for
command-line options
[<keyspaces...>]
List of keyspaces. By default, all keyspacesConfiguring for Snapshots
To demonstrate creating snapshots with Nodetool on the commandline we
have set auto_snapshots setting to false in the cassandra.yaml file:
auto_snapshot: falseAlso set snapshot_before_compaction to false to disable creating
snapshots automatically before compaction:
snapshot_before_compaction: falseCreating Snapshots
Before creating any snapshots, search for snapshots and none will be listed:
$ find -name snapshotsWe shall be using the example keyspaces and tables to create snapshots.
Taking Snapshots of all Tables in a Keyspace
Using the syntax above, create a snapshot called catalog-ks for all the tables
in the catalogkeyspace keyspace:
$ nodetool snapshot --tag catalog-ks catalogkeyspaceresults in
Requested creating snapshot(s) for [catalogkeyspace] with snapshot name [catalog-ks] and
options {skipFlush=false}
Snapshot directory: catalog-ksUsing the find command above, the snapshots and snapshots directories
are now found with listed files similar to:
./cassandra/data/data/catalogkeyspace/journal-296a2d30c22a11e9b1350d927649052c/snapshots
./cassandra/data/data/catalogkeyspace/magazine-446eae30c22a11e9b1350d927649052c/snapshotsSnapshots of all tables in multiple keyspaces may be created similarly:
$ nodetool snapshot --tag catalog-cql-ks catalogkeyspace, cqlkeyspaceTaking Snapshots of Single Table in a Keyspace
To take a snapshot of a single table the nodetool snapshot command
syntax becomes as follows:
$ nodetool snapshot --tag <tag> --table <table> --<keyspace>Using the syntax above, create a snapshot for table magazine in keyspace catalogkeyspace:
$ nodetool snapshot --tag magazine --table magazine catalogkeyspaceresults in
Requested creating snapshot(s) for [catalogkeyspace] with snapshot name [magazine] and
options {skipFlush=false}
Snapshot directory: magazineTaking Snapshot of Multiple Tables from same Keyspace
To take snapshots of multiple tables in a keyspace the list of
Keyspace.table must be specified with option --kt-list.
For example, create snapshots for tables t and t2 in the cqlkeyspace keyspace:
$ nodetool snapshot --kt-list cqlkeyspace.t,cqlkeyspace.t2 --tag multi-tableresults in
Requested creating snapshot(s) for ["CQLKeyspace".t,"CQLKeyspace".t2] with snapshot name [multi-
table] and options {skipFlush=false}
Snapshot directory: multi-tableMultiple snapshots of the same set of tables may be created and tagged with a different name.
As an example, create another snapshot for the same set of tables t and t2 in the cqlkeyspace
keyspace and tag the snapshots differently:
$ nodetool snapshot --kt-list cqlkeyspace.t, cqlkeyspace.t2 --tag multi-table-2results in
Requested creating snapshot(s) for ["CQLKeyspace".t,"CQLKeyspace".t2] with snapshot name [multi-
table-2] and options {skipFlush=false}
Snapshot directory: multi-table-2Taking Snapshot of Multiple Tables from Different Keyspaces
To take snapshots of multiple tables that are in different keyspaces the
command syntax is the same as when multiple tables are in the same
keyspace.
Each <keyspace>.<table> must be specified separately in the
--kt-list option.
For example, create a snapshot for table t in
the cqlkeyspace and table journal in the catalogkeyspace and tag the
snapshot multi-ks.
$ nodetool snapshot --kt-list catalogkeyspace.journal,cqlkeyspace.t --tag multi-ksresults in
Requested creating snapshot(s) for [catalogkeyspace.journal,cqlkeyspace.t] with snapshot
name [multi-ks] and options {skipFlush=false}
Snapshot directory: multi-ksListing Snapshots
To list snapshots use the nodetool listsnapshots command. All the
snapshots that we created in the preceding examples get listed:
$ nodetool listsnapshotsresults in
Snapshot Details:
Snapshot name Keyspace name Column family name True size Size on disk
multi-table cqlkeyspace t2 4.86 KiB 5.67 KiB
multi-table cqlkeyspace t 4.89 KiB 5.7 KiB
multi-ks cqlkeyspace t 4.89 KiB 5.7 KiB
multi-ks catalogkeyspace journal 4.9 KiB 5.73 KiB
magazine catalogkeyspace magazine 4.9 KiB 5.73 KiB
multi-table-2 cqlkeyspace t2 4.86 KiB 5.67 KiB
multi-table-2 cqlkeyspace t 4.89 KiB 5.7 KiB
catalog-ks catalogkeyspace journal 4.9 KiB 5.73 KiB
catalog-ks catalogkeyspace magazine 4.9 KiB 5.73 KiB
Total TrueDiskSpaceUsed: 44.02 KiBFinding Snapshots Directories
The snapshots directories may be listed with find –name snapshots
command:
$ find -name snapshotsresults in
./cassandra/data/data/cqlkeyspace/t-d132e240c21711e9bbee19821dcea330/snapshots
./cassandra/data/data/cqlkeyspace/t2-d993a390c22911e9b1350d927649052c/snapshots
./cassandra/data/data/catalogkeyspace/journal-296a2d30c22a11e9b1350d927649052c/snapshots
./cassandra/data/data/catalogkeyspace/magazine-446eae30c22a11e9b1350d927649052c/snapshotsTo list the snapshots for a particular table first change to the snapshots directory for that table.
For example, list the snapshots for the catalogkeyspace/journal table:
$ cd ./cassandra/data/data/catalogkeyspace/journal-296a2d30c22a11e9b1350d927649052c/snapshots && ls -lresults in
total 0
drwxrwxr-x. 2 ec2-user ec2-user 265 Aug 19 02:44 catalog-ks
drwxrwxr-x. 2 ec2-user ec2-user 265 Aug 19 02:52 multi-ksA snapshots directory lists the SSTable files in the snapshot.
A schema.cql file is also created in each snapshot that defines schema
that can recreate the table with CQL when restoring from a snapshot:
$ cd catalog-ks && ls -lresults in
total 44
-rw-rw-r--. 1 ec2-user ec2-user 31 Aug 19 02:44 manifest.jsonZ
-rw-rw-r--. 4 ec2-user ec2-user 47 Aug 19 02:38 na-1-big-CompressionInfo.db
-rw-rw-r--. 4 ec2-user ec2-user 97 Aug 19 02:38 na-1-big-Data.db
-rw-rw-r--. 4 ec2-user ec2-user 10 Aug 19 02:38 na-1-big-Digest.crc32
-rw-rw-r--. 4 ec2-user ec2-user 16 Aug 19 02:38 na-1-big-Filter.db
-rw-rw-r--. 4 ec2-user ec2-user 16 Aug 19 02:38 na-1-big-Index.db
-rw-rw-r--. 4 ec2-user ec2-user 4687 Aug 19 02:38 na-1-big-Statistics.db
-rw-rw-r--. 4 ec2-user ec2-user 56 Aug 19 02:38 na-1-big-Summary.db
-rw-rw-r--. 4 ec2-user ec2-user 92 Aug 19 02:38 na-1-big-TOC.txt
-rw-rw-r--. 1 ec2-user ec2-user 814 Aug 19 02:44 schema.cqlClearing Snapshots
Snapshots may be cleared or deleted with the nodetool clearsnapshot
command. Either a specific snapshot name must be specified or the –all
option must be specified.
For example, delete a snapshot called magazine from keyspace cqlkeyspace:
$ nodetool clearsnapshot -t magazine cqlkeyspaceor delete all snapshots from cqlkeyspace with the –all option:
$ nodetool clearsnapshot -all cqlkeyspaceIncremental Backups
In the following sections, we shall discuss configuring and creating incremental backups.
Configuring for Incremental Backups
To create incremental backups set incremental_backups to true in
cassandra.yaml.
incremental_backups: trueThis is the only setting needed to create incremental backups.
By default incremental_backups setting is set to false because a new
set of SSTable files is created for each data flush and if several CQL
statements are to be run the backups directory could fill up quickly
and use up storage that is needed to store table data.
Incremental backups may also be enabled on the command line with the nodetool
command nodetool enablebackup.
Incremental backups may be disabled with nodetool disablebackup command.
Status of incremental backups, whether they are enabled may be checked with nodetool statusbackup.
Creating Incremental Backups
After each table is created flush the table data with nodetool flush
command. Incremental backups get created.
$ nodetool flush cqlkeyspace t
$ nodetool flush cqlkeyspace t2
$ nodetool flush catalogkeyspace journal magazineFinding Incremental Backups
Incremental backups are created within the Cassandra’s data directory
within a table directory. Backups may be found with following command.
$ find -name backupsresults in
./cassandra/data/data/cqlkeyspace/t-d132e240c21711e9bbee19821dcea330/backups
./cassandra/data/data/cqlkeyspace/t2-d993a390c22911e9b1350d927649052c/backups
./cassandra/data/data/catalogkeyspace/journal-296a2d30c22a11e9b1350d927649052c/backups
./cassandra/data/data/catalogkeyspace/magazine-446eae30c22a11e9b1350d927649052c/backupsCreating an Incremental Backup
This section discusses how incremental backups are created in more detail using the keyspace and table previously created.
Flush the keyspace and table:
$ nodetool flush cqlkeyspace tA search for backups and a backups directory will list a backup directory,
even if we have added no table data yet.
$ find -name backupsresults in
./cassandra/data/data/cqlkeyspace/t-d132e240c21711e9bbee19821dcea330/backupsChecking the backups directory will show that there are also no backup files:
$ cd ./cassandra/data/data/cqlkeyspace/t-d132e240c21711e9bbee19821dcea330/backups && ls -lresults in
total 0If a row of data is added to the data, running the nodetool flush command will
flush the table data and an incremental backup will be created:
$ nodetool flush cqlkeyspace t
$ cd ./cassandra/data/data/cqlkeyspace/t-d132e240c21711e9bbee19821dcea330/backups && ls -lresults in
total 36
-rw-rw-r--. 2 ec2-user ec2-user 47 Aug 19 00:32 na-1-big-CompressionInfo.db
-rw-rw-r--. 2 ec2-user ec2-user 43 Aug 19 00:32 na-1-big-Data.db
-rw-rw-r--. 2 ec2-user ec2-user 10 Aug 19 00:32 na-1-big-Digest.crc32
-rw-rw-r--. 2 ec2-user ec2-user 16 Aug 19 00:32 na-1-big-Filter.db
-rw-rw-r--. 2 ec2-user ec2-user 8 Aug 19 00:32 na-1-big-Index.db
-rw-rw-r--. 2 ec2-user ec2-user 4673 Aug 19 00:32 na-1-big-Statistics.db
-rw-rw-r--. 2 ec2-user ec2-user 56 Aug 19 00:32 na-1-big-Summary.db
-rw-rw-r--. 2 ec2-user ec2-user 92 Aug 19 00:32 na-1-big-TOC.txt|
note
The |
Adding another row of data and flushing will result in another set of incremental backup files. The SSTable files are timestamped, which distinguishes the first incremental backup from the second:
total 72
-rw-rw-r--. 2 ec2-user ec2-user 47 Aug 19 00:32 na-1-big-CompressionInfo.db
-rw-rw-r--. 2 ec2-user ec2-user 43 Aug 19 00:32 na-1-big-Data.db
-rw-rw-r--. 2 ec2-user ec2-user 10 Aug 19 00:32 na-1-big-Digest.crc32
-rw-rw-r--. 2 ec2-user ec2-user 16 Aug 19 00:32 na-1-big-Filter.db
-rw-rw-r--. 2 ec2-user ec2-user 8 Aug 19 00:32 na-1-big-Index.db
-rw-rw-r--. 2 ec2-user ec2-user 4673 Aug 19 00:32 na-1-big-Statistics.db
-rw-rw-r--. 2 ec2-user ec2-user 56 Aug 19 00:32 na-1-big-Summary.db
-rw-rw-r--. 2 ec2-user ec2-user 92 Aug 19 00:32 na-1-big-TOC.txt
-rw-rw-r--. 2 ec2-user ec2-user 47 Aug 19 00:35 na-2-big-CompressionInfo.db
-rw-rw-r--. 2 ec2-user ec2-user 41 Aug 19 00:35 na-2-big-Data.db
-rw-rw-r--. 2 ec2-user ec2-user 10 Aug 19 00:35 na-2-big-Digest.crc32
-rw-rw-r--. 2 ec2-user ec2-user 16 Aug 19 00:35 na-2-big-Filter.db
-rw-rw-r--. 2 ec2-user ec2-user 8 Aug 19 00:35 na-2-big-Index.db
-rw-rw-r--. 2 ec2-user ec2-user 4673 Aug 19 00:35 na-2-big-Statistics.db
-rw-rw-r--. 2 ec2-user ec2-user 56 Aug 19 00:35 na-2-big-Summary.db
-rw-rw-r--. 2 ec2-user ec2-user 92 Aug 19 00:35 na-2-big-TOC.txtRestoring from Incremental Backups and Snapshots
The two main tools/commands for restoring a table after it has been dropped are:
-
sstableloader
-
nodetool import
A snapshot contains essentially the same set of SSTable files as an
incremental backup does with a few additional files. A snapshot includes
a schema.cql file for the schema DDL to create a table in CQL. A table
backup does not include DDL which must be obtained from a snapshot when
restoring from an incremental backup.