













Read repair
Read Repair is the process of repairing data replicas during a read request. If all replicas involved in a read request at the given read consistency level are consistent the data is returned to the client and no read repair is needed. But if the replicas involved in a read request at the given consistency level are not consistent a read repair is performed to make replicas involved in the read request consistent. The most up-to-date data is returned to the client. The read repair runs in the foreground and is blocking in that a response is not returned to the client until the read repair has completed and up-to-date data is constructed.
Expectation of Monotonic Quorum Reads
Cassandra uses a blocking read repair to ensure the expectation of "monotonic quorum reads" i.e. that in 2 successive quorum reads, it’s guaranteed the 2nd one won’t get something older than the 1st one, and this even if a failed quorum write made a write of the most up to date value only to a minority of replicas. "Quorum" means majority of nodes among replicas.
Table level configuration of monotonic reads
Cassandra 4.0 adds support for table level configuration of monotonic
reads
(CASSANDRA-14635).
The read_repair table option has been added to table schema, with the
options blocking (default), and none.
The read_repair option configures the read repair behavior to allow
tuning for various performance and consistency behaviors. Two
consistency properties are affected by read repair behavior.
-
Monotonic Quorum Reads: Provided by
BLOCKING. Monotonic quorum reads prevents reads from appearing to go back in time in some circumstances. When monotonic quorum reads are not provided and a write fails to reach a quorum of replicas, it may be visible in one read, and then disappear in a subsequent read. -
Write Atomicity: Provided by
NONE. Write atomicity prevents reads from returning partially applied writes. Cassandra attempts to provide partition level write atomicity, but since only the data covered by aSELECTstatement is repaired by a read repair, read repair can break write atomicity when data is read at a more granular level than it is written. For example read repair can break write atomicity if you write multiple rows to a clustered partition in a batch, but then select a single row by specifying the clustering column in aSELECTstatement.
The available read repair settings are:
Blocking
The default setting. When read_repair is set to BLOCKING, and a read
repair is started, the read will block on writes sent to other replicas
until the CL is reached by the writes. Provides monotonic quorum reads,
but not partition level write atomicity.
None
When read_repair is set to NONE, the coordinator will reconcile any
differences between replicas, but will not attempt to repair them.
Provides partition level write atomicity, but not monotonic quorum
reads.
An example of using the NONE setting for the read_repair option is
as follows:
CREATE TABLE ks.tbl (k INT, c INT, v INT, PRIMARY KEY (k,c)) with read_repair='NONE'");Read Repair Example
To illustrate read repair with an example, consider that a client sends
a read request with read consistency level TWO to a 5-node cluster as
illustrated in Figure 1. Read consistency level determines how many
replica nodes must return a response before the read request is
considered successful.
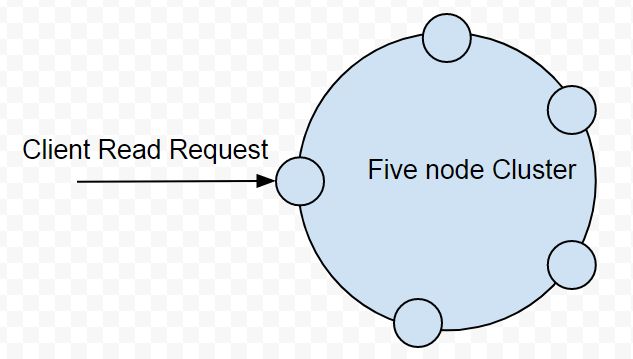
Figure 1. Client sends read request to a 5-node Cluster
Three nodes host replicas for the requested data as illustrated in
Figure 2. With a read consistency level of TWO two replica nodes must
return a response for the read request to be considered successful. If
the node the client sends request to hosts a replica of the data
requested only one other replica node needs to be sent a read request
to. But if the receiving node does not host a replica for the requested
data the node becomes a coordinator node and forwards the read request
to a node that hosts a replica. A direct read request is forwarded to
the fastest node (as determined by dynamic snitch) as shown in Figure 2.
A direct read request is a full read and returns the requested data.
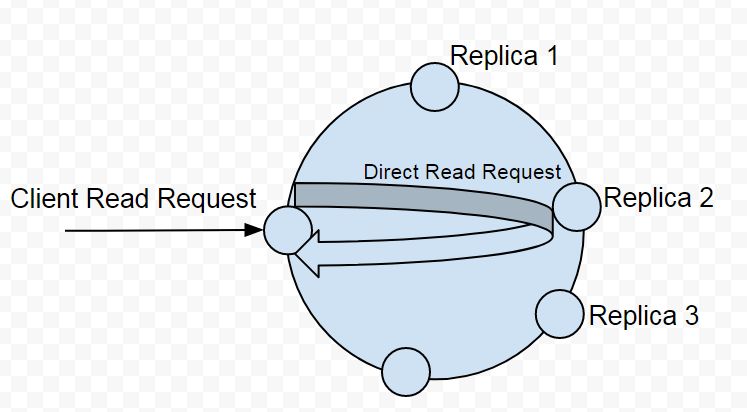
Figure 2. Direct Read Request sent to Fastest Replica Node
Next, the coordinator node sends the requisite number of additional
requests to satisfy the consistency level, which is TWO. The
coordinator node needs to send one more read request for a total of two.
All read requests additional to the first direct read request are digest
read requests. A digest read request is not a full read and only returns
the hash value of the data. Only a hash value is returned to reduce the
network data traffic. In the example being discussed the coordinator
node sends one digest read request to a node hosting a replica as
illustrated in Figure 3.
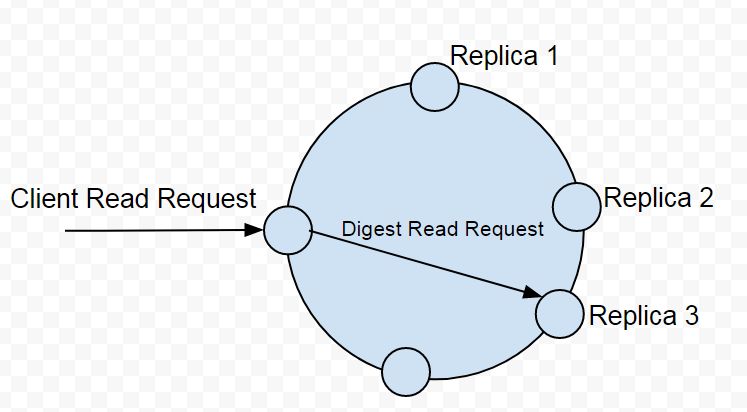
Figure 3. Coordinator Sends a Digest Read Request
The coordinator node has received a full copy of data from one node and
a hash value for the data from another node. To compare the data
returned a hash value is calculated for the full copy of data. The two
hash values are compared. If the hash values are the same no read repair
is needed and the full copy of requested data is returned to the client.
The coordinator node only performed a total of two replica read request
because the read consistency level is TWO in the example. If the
consistency level were higher such as THREE, three replica nodes would
need to respond to a read request and only if all digest or hash values
were to match with the hash value of the full copy of data would the
read request be considered successful and the data returned to the
client.
But, if the hash value/s from the digest read request/s are not the same as the hash value of the data from the full read request of the first replica node it implies that an inconsistency in the replicas exists. To fix the inconsistency a read repair is performed.
For example, consider that that digest request returns a hash value that is not the same as the hash value of the data from the direct full read request. We would need to make the replicas consistent for which the coordinator node sends a direct (full) read request to the replica node that it sent a digest read request to earlier as illustrated in Figure 4.
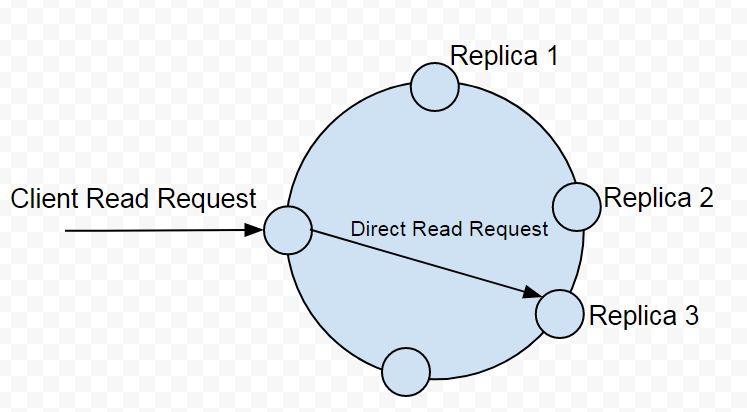
Figure 4. Coordinator sends Direct Read Request to Replica Node it had sent Digest Read Request to
After receiving the data from the second replica node the coordinator
has data from two of the replica nodes. It only needs two replicas as
the read consistency level is TWO in the example. Data from the two
replicas is compared and based on the timestamps the most recent replica
is selected. Data may need to be merged to construct an up-to-date copy
of data if one replica has data for only some of the columns. In the
example, if the data from the first direct read request is found to be
outdated and the data from the second full read request to be the latest
read, repair needs to be performed on Replica 2. If a new up-to-date
data is constructed by merging the two replicas a read repair would be
needed on both the replicas involved. For example, a read repair is
performed on Replica 2 as illustrated in Figure 5.
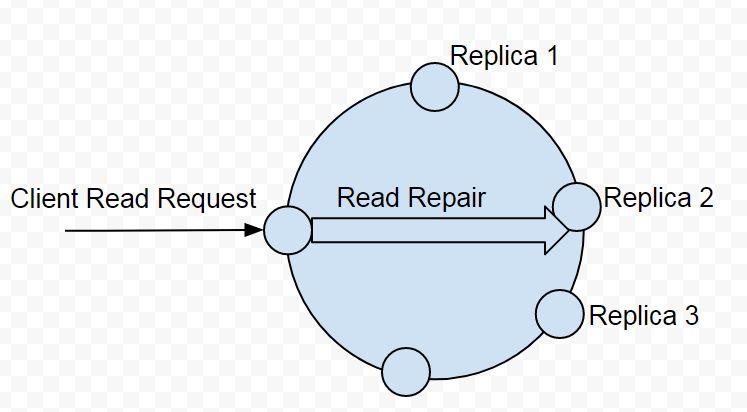
Figure 5. Coordinator performs Read Repair
The most up-to-date data is returned to the client as illustrated in Figure 6. From the three replicas Replica 1 is not even read and thus not repaired. Replica 2 is repaired. Replica 3 is the most up-to-date and returned to client.
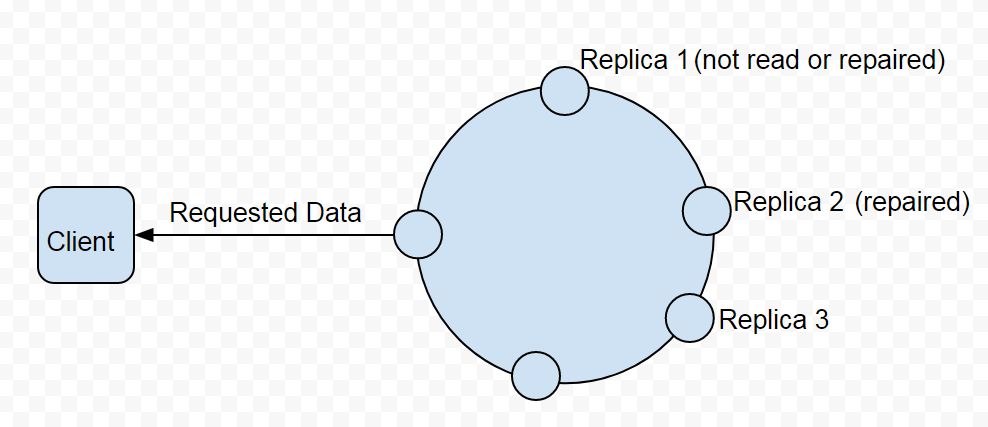
Figure 6. Most up-to-date Data returned to Client
Read Consistency Level and Read Repair
The read consistency is most significant in determining if a read repair needs to be performed. As discussed in Table 1 a read repair is not needed for all of the consistency levels.
Table 1. Read Repair based on Read Consistency Level
| Read Consistency Level | Description |
|---|---|
ONE |
Read repair is not performed as the data from the first direct read request satisfies the consistency level ONE. No digest read requests are involved for finding mismatches in data. |
TWO |
Read repair is performed if inconsistencies in data are found as determined by the direct and digest read requests. |
THREE |
Read repair is performed if inconsistencies in data are found as determined by the direct and digest read requests. |
LOCAL_ONE |
Read repair is not performed as the data from the direct read request from the closest replica satisfies the consistency level LOCAL_ONE.No digest read requests are involved for finding mismatches in data. |
LOCAL_QUORUM |
Read repair is performed if inconsistencies in data are found as determined by the direct and digest read requests. |
QUORUM |
Read repair is performed if inconsistencies in data are found as determined by the direct and digest read requests. |
If read repair is performed it is made only on the replicas that are not up-to-date and that are involved in the read request. The number of replicas involved in a read request would be based on the read consistency level; in the example it is two.
Improved Read Repair Blocking Behavior in Cassandra 4.0
Cassandra 4.0 makes two improvements to read repair blocking behavior (CASSANDRA-10726).
-
Speculative Retry of Full Data Read Requests. Cassandra 4.0 makes use of speculative retry in sending read requests (full, not digest) to replicas if a full data response is not received, whether in the initial full read request or a full data read request during read repair. With speculative retry if it looks like a response may not be received from the initial set of replicas Cassandra sent messages to, to satisfy the consistency level, it speculatively sends additional read request to un-contacted replica/s. Cassandra 4.0 will also speculatively send a repair mutation to a minority of nodes not involved in the read repair data read / write cycle with the combined contents of all un-acknowledged mutations if it looks like one may not respond. Cassandra accepts acks from them in lieu of acks from the initial mutations sent out, so long as it receives the same number of acks as repair mutations transmitted.
-
Only blocks on Full Data Responses to satisfy the Consistency Level. Cassandra 4.0 only blocks for what is needed for resolving the digest mismatch and wait for enough full data responses to meet the consistency level, no matter whether it’s speculative retry or read repair chance. As an example, if it looks like Cassandra might not receive full data requests from everyone in time, it sends additional requests to additional replicas not contacted in the initial full data read. If the collection of nodes that end up responding in time end up agreeing on the data, the response from the disagreeing replica that started the read repair is not considered, and won’t be included in the response to the client, preserving the expectation of monotonic quorum reads.
Diagnostic Events for Read Repairs
Cassandra 4.0 adds diagnostic events for read repair (CASSANDRA-14668) that can be used for exposing information such as:
-
Contacted endpoints
-
Digest responses by endpoint
-
Affected partition keys
-
Speculated reads / writes
-
Update oversized
Background Read Repair
Background read repair, which was configured using read_repair_chance
and dclocal_read_repair_chance settings in cassandra.yaml is removed
Cassandra 4.0
(CASSANDRA-13910).
Read repair is not an alternative for other kind of repairs such as full repairs or replacing a node that keeps failing. The data returned even after a read repair has been performed may not be the most up-to-date data if consistency level is other than one requiring response from all replicas.