













RDBMS Design
When you set out to build a new data-driven application that will use a relational database, you might start by modeling the domain as a set of properly normalized tables and use foreign keys to reference related data in other tables.
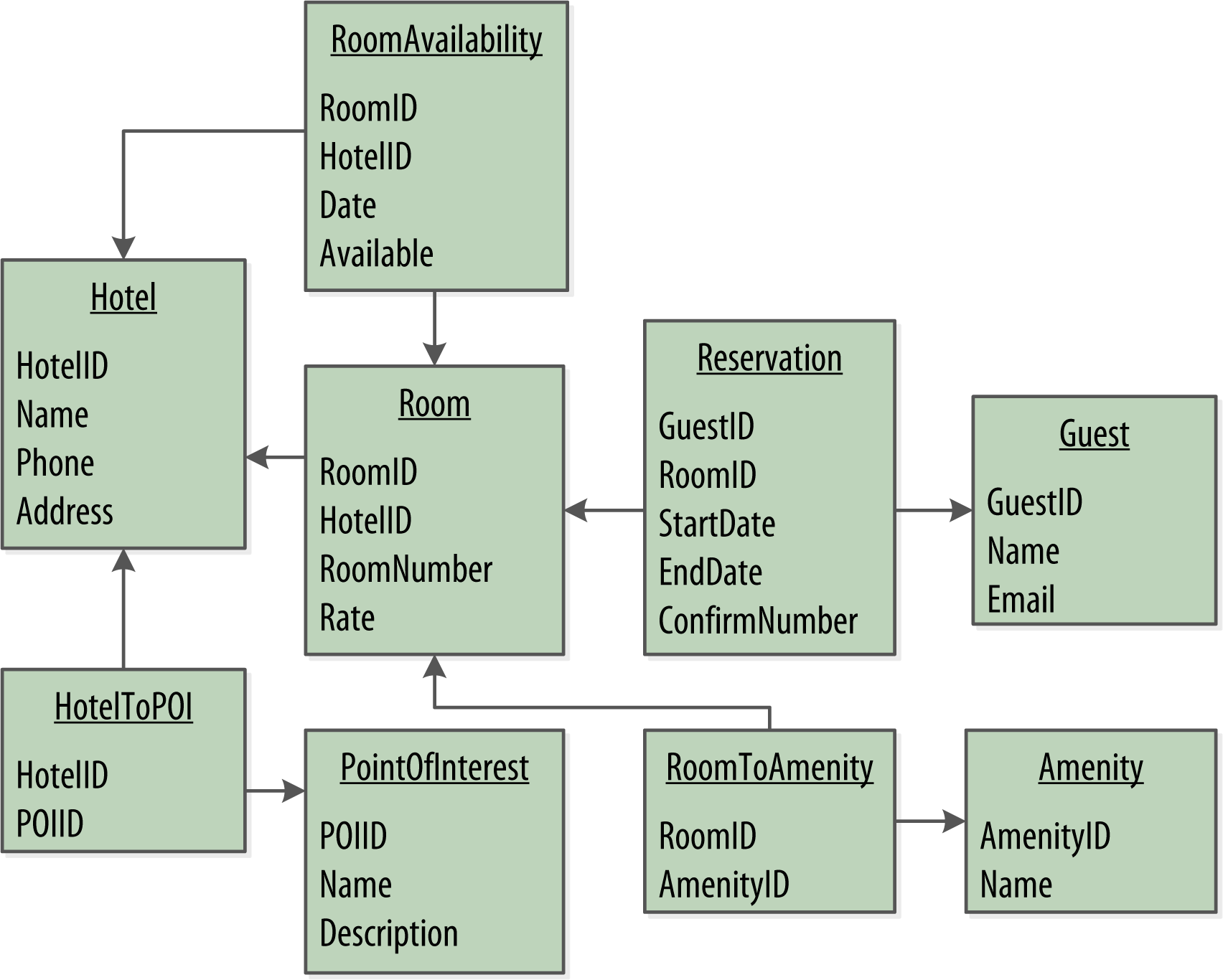
The figure below shows how you might represent the data storage for your application using a relational database model. The relational model includes a couple of “join” tables in order to realize the many-to-many relationships from the conceptual model of hotels-to-points of interest, rooms-to-amenities, rooms-to-availability, and guests-to-rooms (via a reservation).
Design Differences Between RDBMS and Cassandra
Let’s take a minute to highlight some of the key differences in doing data modeling for Cassandra versus a relational database.
No joins
You cannot perform joins in Cassandra. If you have designed a data model and find that you need something like a join, you’ll have to either do the work on the client side, or create a denormalized second table that represents the join results for you. This latter option is preferred in Cassandra data modeling. Performing joins on the client should be a very rare case; you really want to duplicate (denormalize) the data instead.
No referential integrity
Although Cassandra supports features such as lightweight transactions and batches, Cassandra itself has no concept of referential integrity across tables. In a relational database, you could specify foreign keys in a table to reference the primary key of a record in another table. But Cassandra does not enforce this. It is still a common design requirement to store IDs related to other entities in your tables, but operations such as cascading deletes are not available.
Denormalization
In relational database design, you are often taught the importance of normalization. This is not an advantage when working with Cassandra because it performs best when the data model is denormalized. It is often the case that companies end up denormalizing data in relational databases as well. There are two common reasons for this. One is performance. Companies simply can’t get the performance they need when they have to do so many joins on years’ worth of data, so they denormalize along the lines of known queries. This ends up working, but goes against the grain of how relational databases are intended to be designed, and ultimately makes one question whether using a relational database is the best approach in these circumstances.
A second reason that relational databases get denormalized on purpose is a business document structure that requires retention. That is, you have an enclosing table that refers to a lot of external tables whose data could change over time, but you need to preserve the enclosing document as a snapshot in history. The common example here is with invoices. You already have customer and product tables, and you’d think that you could just make an invoice that refers to those tables. But this should never be done in practice. Customer or price information could change, and then you would lose the integrity of the invoice document as it was on the invoice date, which could violate audits, reports, or laws, and cause other problems.
In the relational world, denormalization violates Codd’s normal forms, and you try to avoid it. But in Cassandra, denormalization is, well, perfectly normal. It’s not required if your data model is simple. But don’t be afraid of it.
Historically, denormalization in Cassandra has required designing and
managing multiple tables using techniques described in this
documentation. Beginning with the 3.0 release, Cassandra provides a
feature known as materialized views <materialized-views> which allows
you to create multiple denormalized views of data based on a base table
design. Cassandra manages materialized views on the server, including
the work of keeping the views in sync with the table.
Query-first design
Relational modeling, in simple terms, means that you start from the conceptual domain and then represent the nouns in the domain in tables. You then assign primary keys and foreign keys to model relationships. When you have a many-to-many relationship, you create the join tables that represent just those keys. The join tables don’t exist in the real world, and are a necessary side effect of the way relational models work. After you have all your tables laid out, you can start writing queries that pull together disparate data using the relationships defined by the keys. The queries in the relational world are very much secondary. It is assumed that you can always get the data you want as long as you have your tables modeled properly. Even if you have to use several complex subqueries or join statements, this is usually true.
By contrast, in Cassandra you don’t start with the data model; you start with the query model. Instead of modeling the data first and then writing queries, with Cassandra you model the queries and let the data be organized around them. Think of the most common query paths your application will use, and then create the tables that you need to support them.
Detractors have suggested that designing the queries first is overly constraining on application design, not to mention database modeling. But it is perfectly reasonable to expect that you should think hard about the queries in your application, just as you would, presumably, think hard about your relational domain. You may get it wrong, and then you’ll have problems in either world. Or your query needs might change over time, and then you’ll have to work to update your data set. But this is no different from defining the wrong tables, or needing additional tables, in an RDBMS.
Designing for optimal storage
In a relational database, it is frequently transparent to the user how tables are stored on disk, and it is rare to hear of recommendations about data modeling based on how the RDBMS might store tables on disk. However, that is an important consideration in Cassandra. Because Cassandra tables are each stored in separate files on disk, it’s important to keep related columns defined together in the same table.
A key goal that you will see as you begin creating data models in Cassandra is to minimize the number of partitions that must be searched in order to satisfy a given query. Because the partition is a unit of storage that does not get divided across nodes, a query that searches a single partition will typically yield the best performance.
Sorting is a design decision
In an RDBMS, you can easily change the order in which records are
returned to you by using ORDER BY in your query. The default sort
order is not configurable; by default, records are returned in the order
in which they are written. If you want to change the order, you just
modify your query, and you can sort by any list of columns.
In Cassandra, however, sorting is treated differently; it is a design
decision. The sort order available on queries is fixed, and is
determined entirely by the selection of clustering columns you supply in
the CREATE TABLE command. The CQL SELECT statement does support
ORDER BY semantics, but only in the order specified by the clustering
columns.
Material adapted from Cassandra, The Definitive Guide. Published by O’Reilly Media, Inc. Copyright © 2020 Jeff Carpenter, Eben Hewitt. All rights reserved. Used with permission.