













Reaper is an open source tool written in Java and built with Dropwizard to schedule and orchestrate repairs of Apache Cassandra clusters. It was originally designed and open-sourced by Spotify in an attempt to automate repairs while applying best practices from their solid production experience.
Repair Challenges
Anti-entropy repair is traditionally performed using the nodetool repair command. It can be performed in two ways, full or incremental, and configured to repair various token ranges: all, primary range, or sub-range. Add to this different validation compaction orchestration settings (sequential, parallel, and data center aware), the fact that anti-compaction may trigger in some cases, and you’re down a rabbit hole of complexity. All this for an operation that is mandatory and should be simple to run. In the 1.x/2.x days of Cassandra (and probably after that), some operators simply gave up on repairing their clusters due to the difficulties involved in completing the operation successfully without impacting SLAs. The main problems encountered during repairs were:
-
A high number of pending compactions and SSTables on disk
-
Repairs taking longer than the tombstones GC grace period
-
High cluster load due to repair pressure
-
Blocked/never-ending repairs
-
A repair that isn’t resumable in case of failure
-
vnodes made the operation very long and challenging to perform
Reaper performs safe repairs
Reaper was built to address those issues and make repairs as safe and reliable as possible. It splits the repair operations into evenly sized subranges and schedules them so that:
-
All nodes are kept busy repairing small units of data if possible
-
A single segment is running on a node at once
-
Segments lasting too long are terminated and re-scheduled
-
Failed segments get replayed in case of a transient failure
-
Pending compactions are monitored to pause segment scheduling, preventing overload
-
Repairs can be paused
The tool also supports incremental repair, which should be safely usable starting with Cassandra 4.0. Since Cassandra 3.0, Reaper can create segments with several token ranges to reduce the overhead of vnodes on repairs. Such ranges will be repaired in a single job by Cassandra as segments will only contain ranges that are replicated on the same set of nodes.
Reaper Features
Reaper ships with a REST API, a command-line tool (spreaper) and a Web UI:
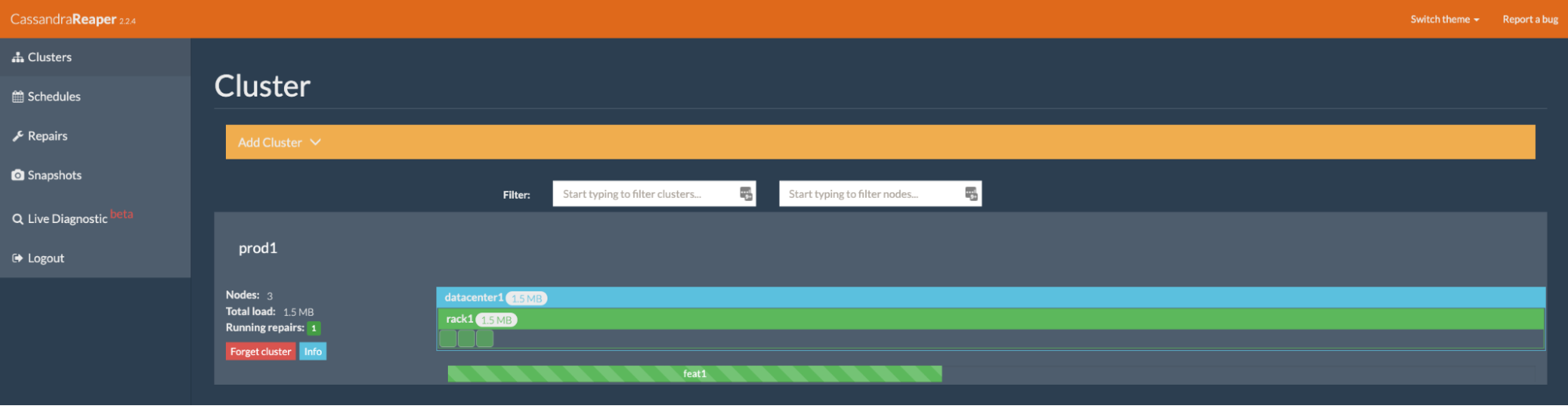
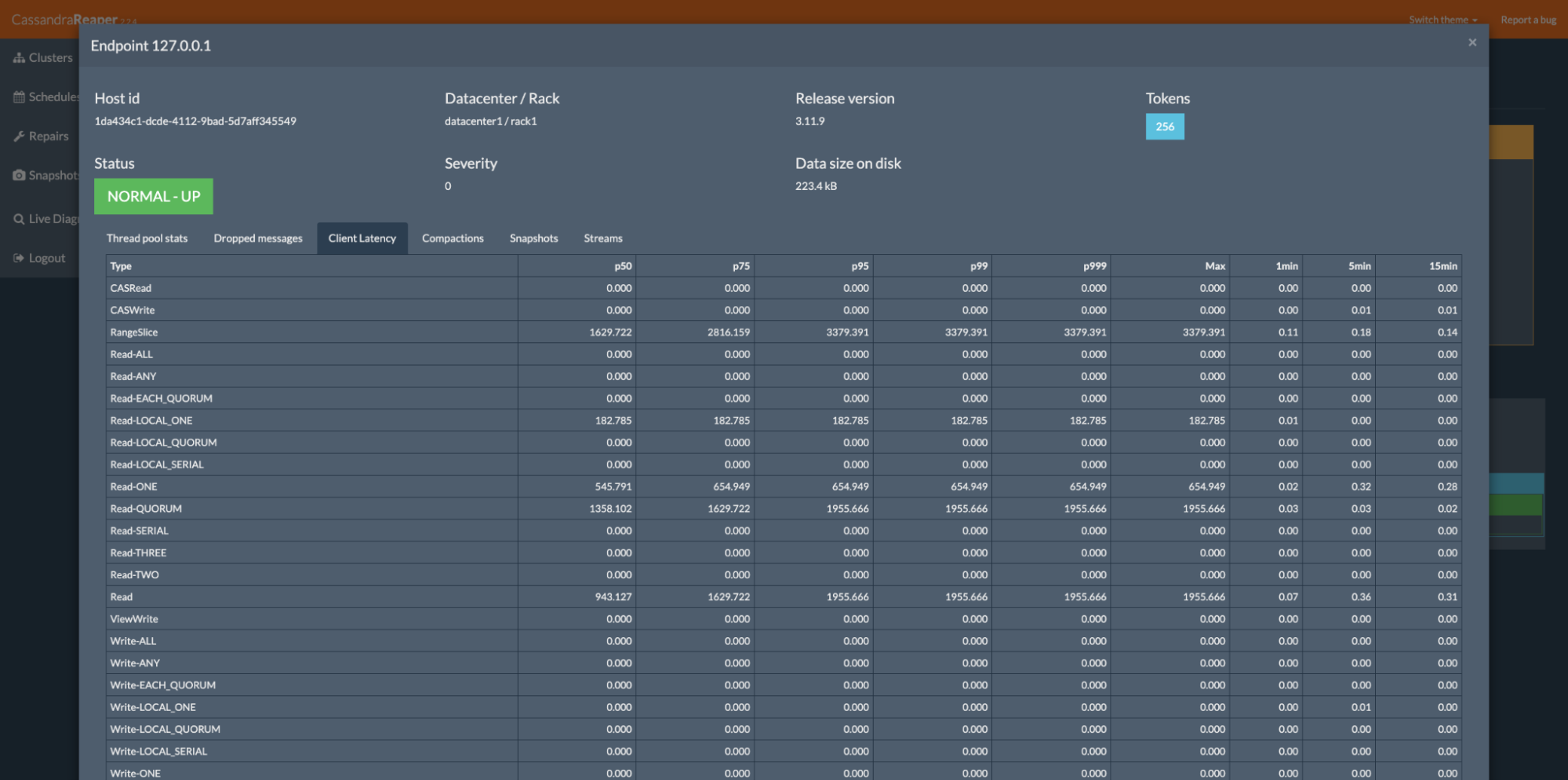
It collects and displays runtime Cassandra metrics, running compactions and ongoing streaming sessions:
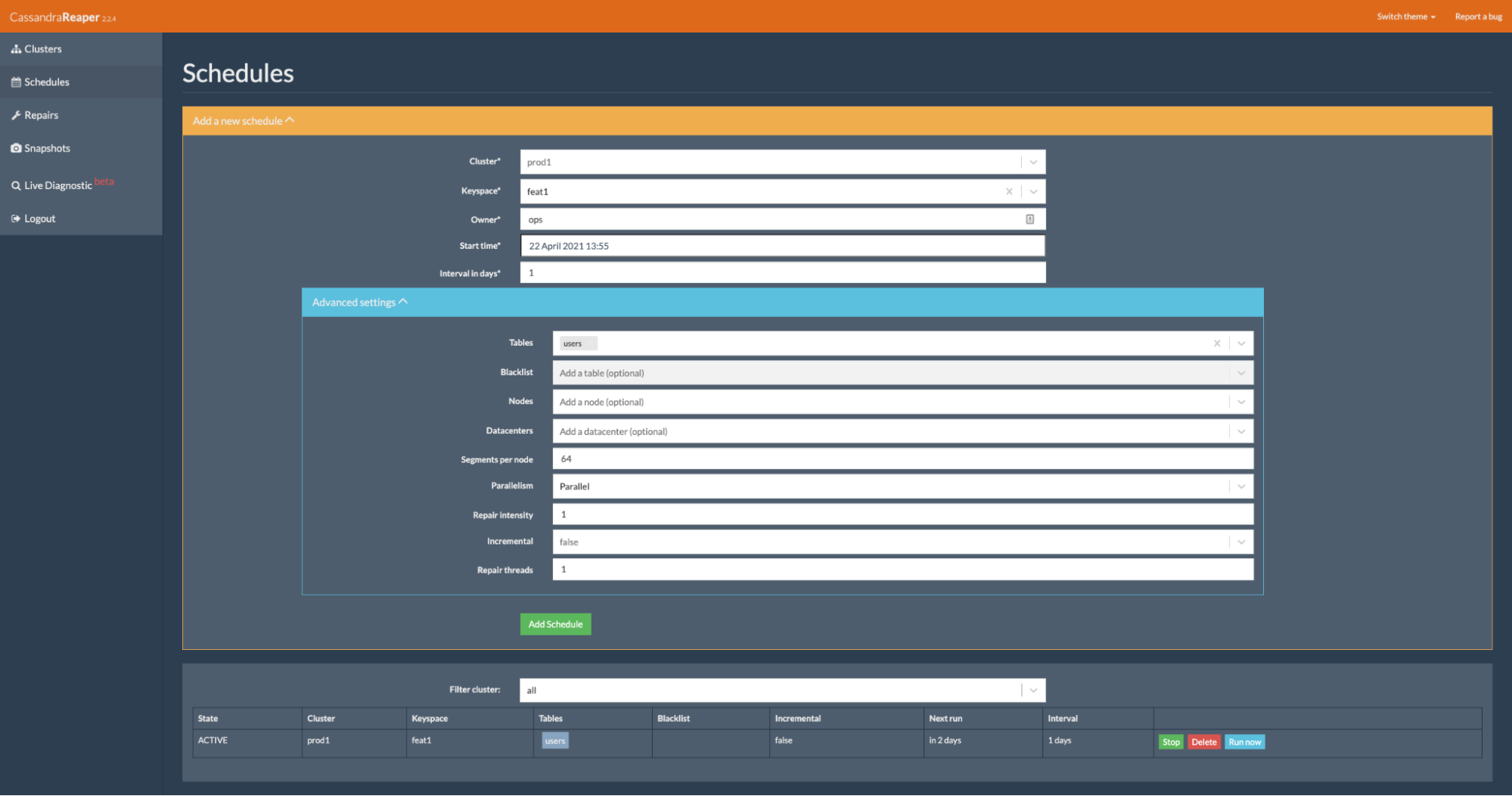
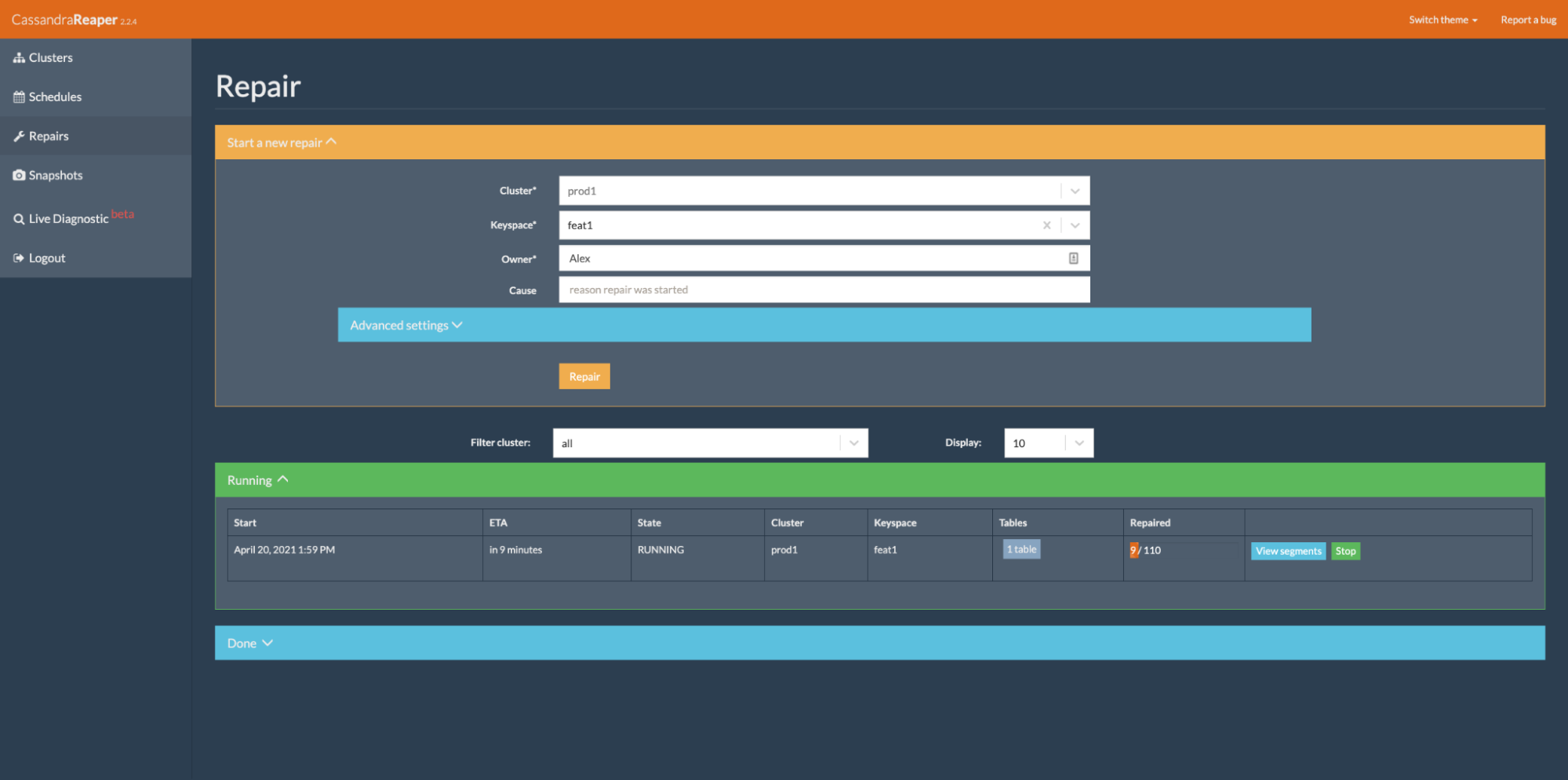
Reaper ships with a scheduler for recurring repairs but can also perform on-demand one-off repairs:
It’s easy to install as a tarball, a Docker container, or deb/rpm packages and can be deployed in various ways to accommodate your cluster’s architecture. A single Reaper instance is capable of managing repairs on dozens of Cassandra clusters but several instances can be deployed to provide high availability or adapt to JMX restrictions in your network:
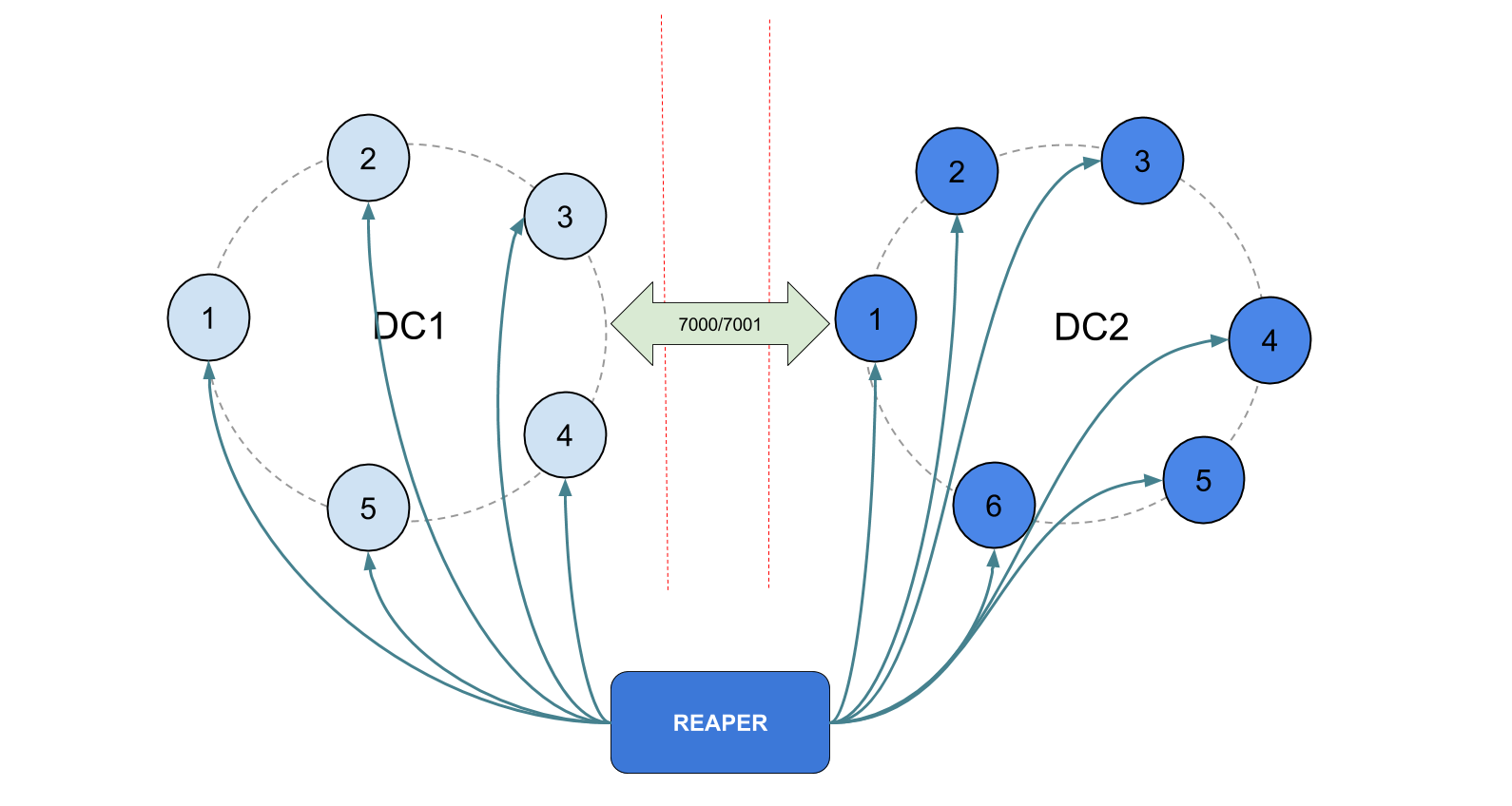
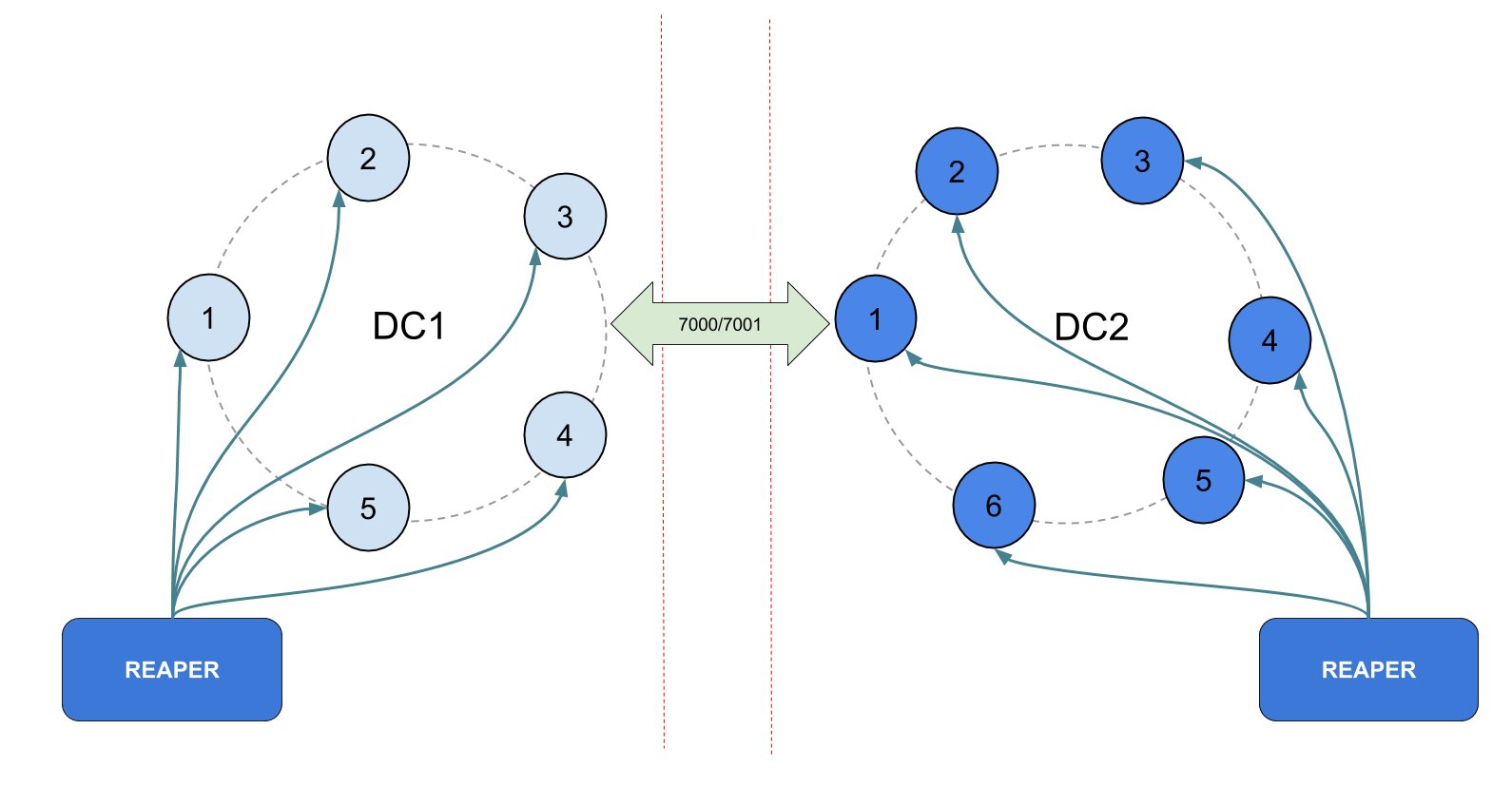
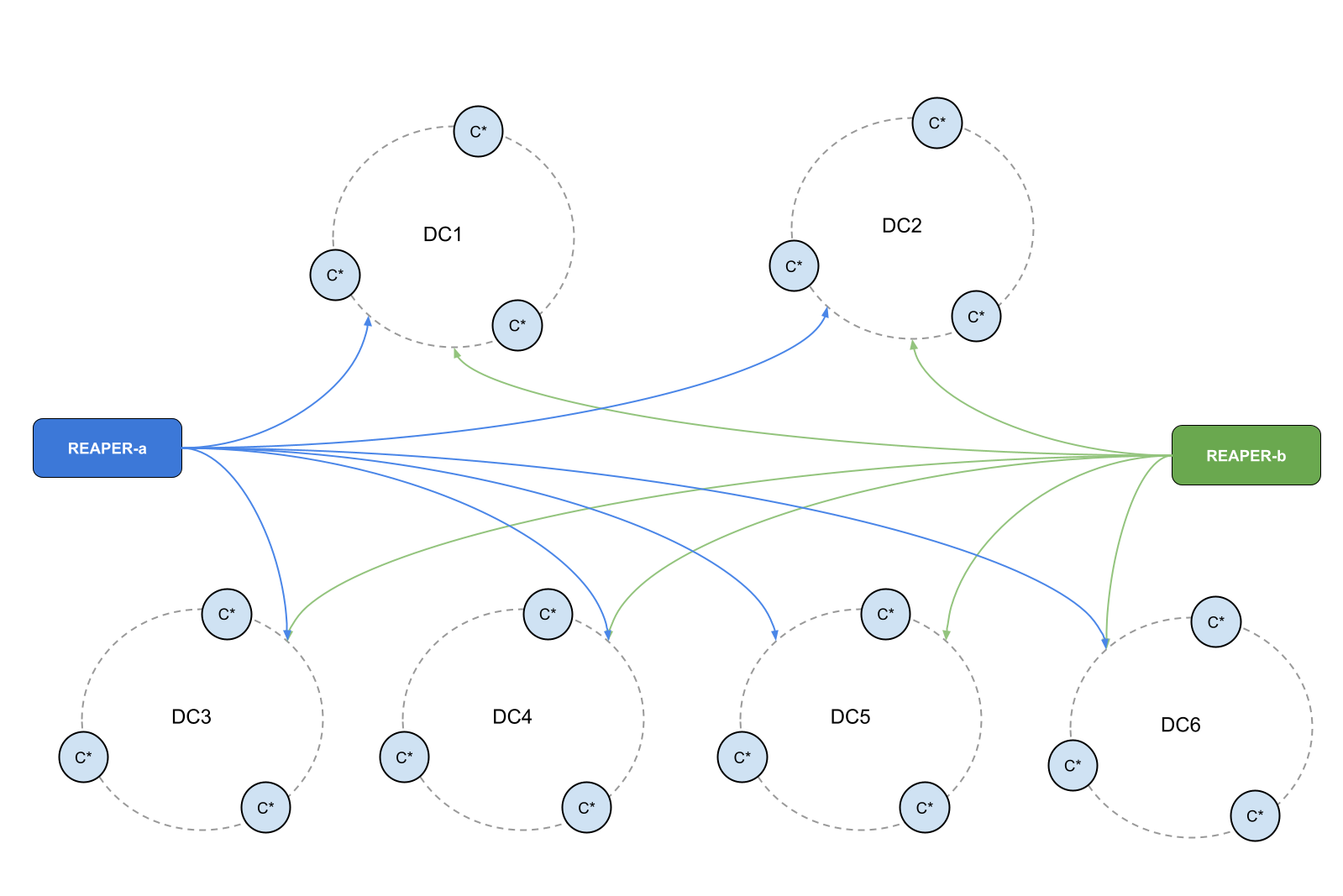
If JMX is restricted to local access, Reaper can even be deployed as a sidecar:
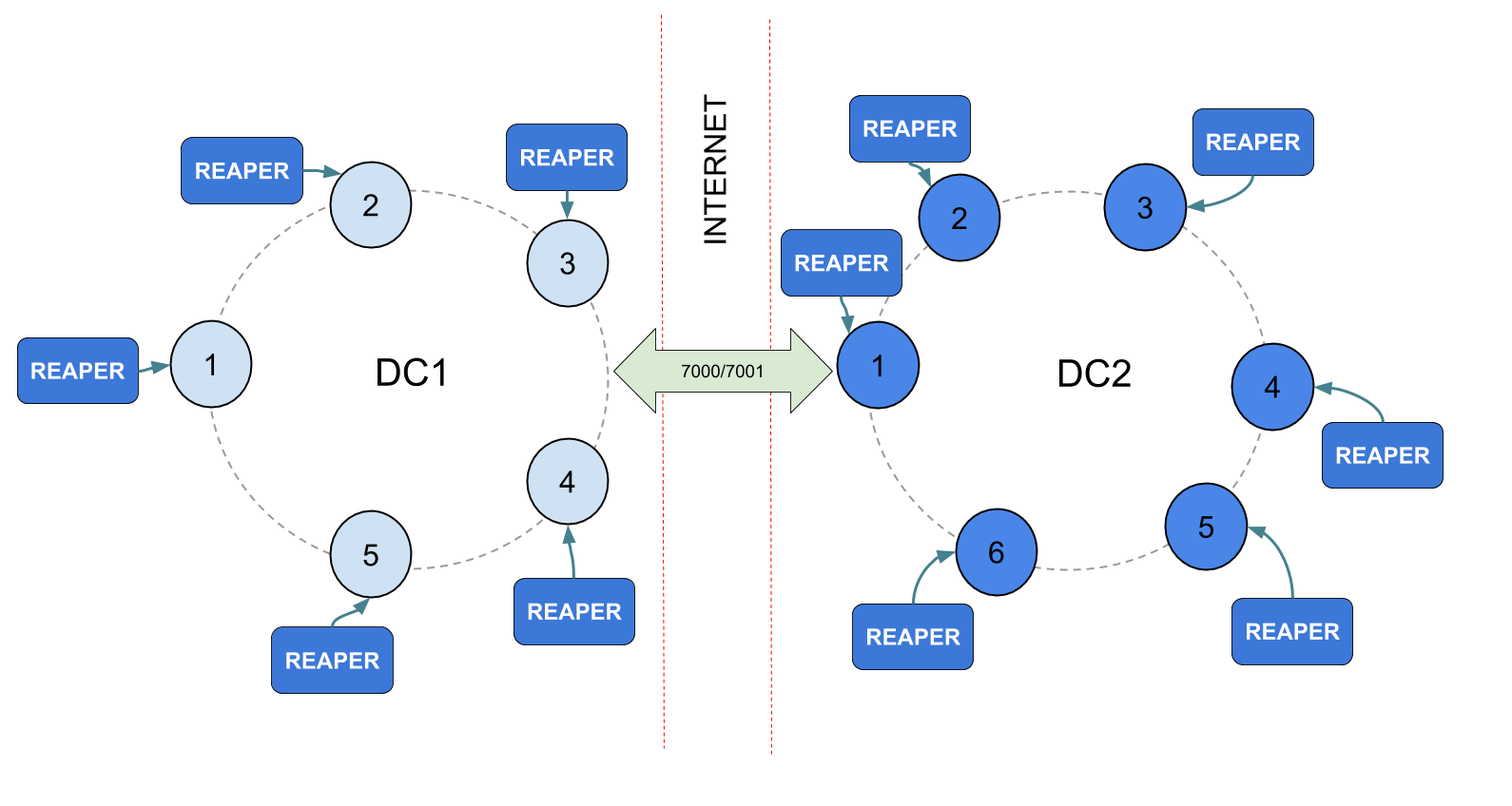
Reaper also can listen and display live Cassandra’s emitted Diagnostic Events.
In Cassandra 4.0 internal system “diagnostic events” have become available via the work done in CASSANDRA-12944. These allow us to observe internal Cassandra events, for example, in unit tests, and with external tools. These diagnostic events provide operational monitoring and troubleshooting beyond logs and metrics.
Reaper can use Postgres and Cassandra itself as a storage backend for its data and can repair all Cassandra versions since 1.2 up to the latest 4.0.
To make Reaper more efficient, segment orchestration was recently revamped and modernized. It opened for a long-awaited feature: fully concurrent repairs for different keyspaces and tables. These changes also introduced a long-awaited feature by allowing fully concurrent repairs for different keyspaces/tables.
You can find more details on these changes in the 2.2 release blog post.
Note: the latest release is 2.3.1.
Eager to try Reaper?
Head over to the cassandra-reaper.io website, which contains all information you’ll need to get started, install Reaper and stop worrying about repairs!
This article by Alexander Dejanovski was previously published on JAXEnter.com.