














One of the new features of Apache Cassandra 4.1, introduced with enhancement proposal #11 (CEP-11), is support for alternative memtable implementations. This feature enables developers to implement new memtable solutions and for users to select a memtable implementation and configuration for each individual table in the database.
This is enabled by a new memtable option in CREATE TABLE and ALTER TABLE statements that specifies the memtable configuration out of a set of options defined in cassandra.yaml, for example:
CREATE TABLE heavy_use … WITH memtable = 'sharded';
where the 'sharded' configuration is defined in cassandra.yaml as
Memtable: Configurations: Sharded: class_name: ShardedSkipListMemtable Parameters: shards: 32 serialize_writes: false
Apache Cassandra 4.1 comes with only a proof-of-concept alternative memtable implementation, which is a sharded skip-list solution that splits the memtable into several shards that cover roughly the same portion of the token space served by the node. This enables writes to different shards to apply independently, without any congestion during modification of the data structure, which is known to enable higher memtable performance for typical Cassandra workloads. The example above shows how this implementation can be selected. It takes two parameters:
-
shards- the number of shards to split the memtable into. -
serialize_writes- whether to lock the memtable shard during mutations.
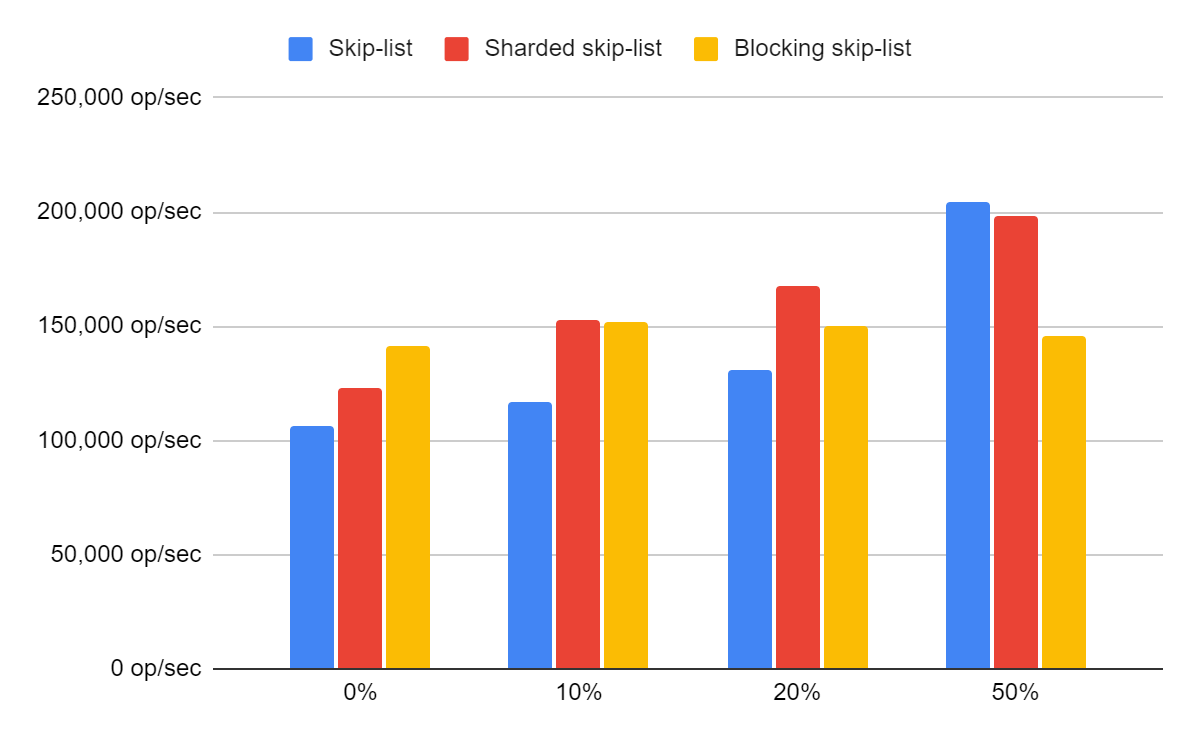
Locking is provided as an option. This avoids wasting processing time and memtable space when multiple concurrent modifications prepare conflicting mutations on the same partition during congested lock-free modification. Locking will result in lower peak write throughput, but may improve the longer-term sustained throughput because of storing slightly more information in each flushed SSTable and giving more CPU time to compaction. The table below shows an example of the average throughput achieved while writing 100GB of key-value data, with 10% reads, and with the given percentage of skew, i.e., accesses hitting the same individual row.
The project will be building on this feature and in the near future, the API will be used to enable two exciting developments:
-
Intel’s persistent memory memtable (CASSANDRA-13981), a memtable-only storage system promising extremely low latencies when suitable hardware is used.
-
A Trie-based memtable (CEP-19, CASSANDRA-17240), which promises significant improvements in performance and garbage collection overheads.